LLM 1.3. 'Hello, I am Featureiman..' - Coding LLM Architecture
2025-11-15
I’ve just finished chapter 4 of Sebastian Raschka's book. In this one, he learns how to code different building blocks of an LLM and how to assemble them into a GPT-like model. So - that is what I've implemented.
In this chapter, the overview of the GPT architecture is explained, as shown below (source: Sebastian Raschka)
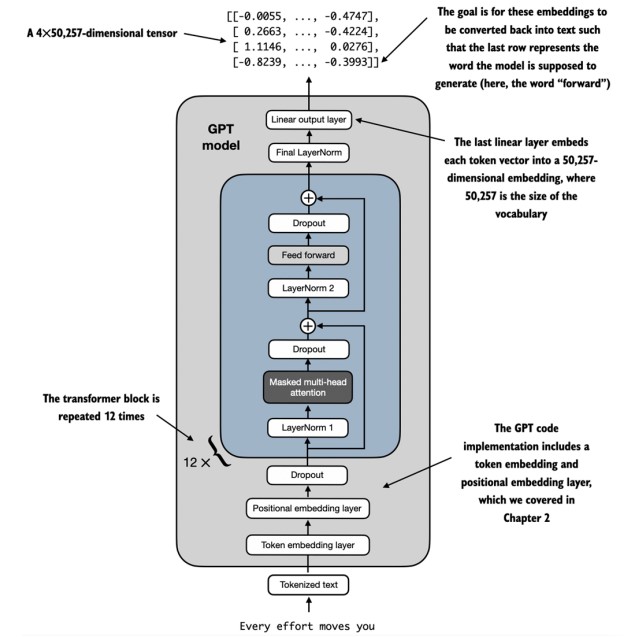
What I've just learned
Chapter 4 - Implementing a GPT model from Scratch to Generate Text
- Configuration - defines (in this example GPT-2 structure is used) a 124M parameter GPT model with 12 layers, 12 attention heads, 768 embedding dimensions and a vocabulary of 50,257 tokens.
In GPT_CONFIG_124M implemented are: no. of unique tokens (GPT-2's BPE vocabulary), maximum sequential length the model can process, dimension of token/position embeddings, no. of parallel attention mechanisms, no. of transformer blocks stacked, probability of dropping neurons and bias (not used as of now).
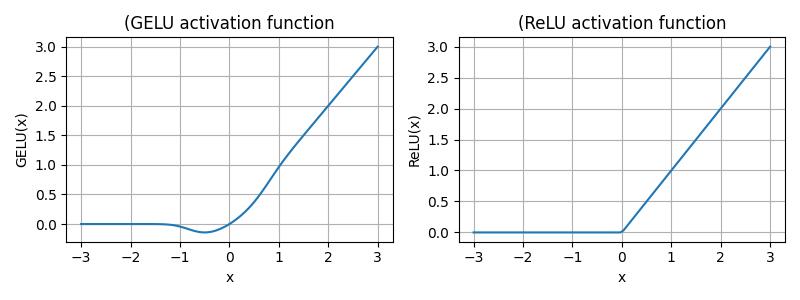
- GELU activation function - in comparison to ReLU, it is more smooth (no sharp corner at x=0 --> better gradients), non-monotonic and related to expected value under Gaussian noise.
For large positive/negative x values, it behaves like ReLU, however around x=0 it performs - unlike ReLU - a smooth transition.
Multi-Head Attention implementation - described in chapter 3, now in practical use
FeedForward Network - two-layer neural network with GELU activation, which expands to 4x the embedding dimension (so, in this case, 768 -> 3072)
Expand -> Activate -> Compress
It expands to 4x, so it creates a bottleneck that forces the model to learn the compressed representations. The expansion allows the model to learn complex non-linear transformations. In the end, it compresses back to original size and integrates the features that were learned.
FFN processes each token independently. After tokens "talk to each other" (attention), each token needs to "think" about what it learned (feedforward)
Layer Normalization - normalizes activations across the embedding dimension. Each token's embedding has to have mean=0 and variance=1, then learnable scaling and shifting is applied. Stabilizes training and allows higher learning rates.
Transformer Block - combines attention + feedforward with residual connections and layer normalization.
So, putting it all together.
First sublayer includes multi-head attention (prenormalization, attention, dropout + residual connection), second sublayer feedforward (prenormalization, feedfoward, dropout + residual connection)
Why residual connections (x + shortcut)?
Allows gradients to flow directly through the network. Model can learn to keep information unchanged if needed. Without residuals, very deep networks are hard to train
Flow: Input → Norm → Attention → Dropout → (+) → Norm → FFN → Dropout → (+) → Output
Complete GPT Model implementation with token embeddings, positional embeddings, transformer blocks and output head
Text Generation
Results
What happens:
- Input:
[15496, 11, 314, 716]("Hello, I am") - Model predicts next token:
[27018] - New input:
[15496, 11, 314, 716, 27018] - Model predicts next token:
[24086] - ... repeat 6 times
Output: tensor([[15496, 11, 314, 716, 27018, 24086, 47843, 30961, 42348, 7267]])
Length: 10
Result: "Hello, I am Featureiman Byeswickattribute argue"
As of now, model is randomly initialized, soo..it doesn't know the language - that's why the output looks gibberish. I will train it in the next chapter!!! I have trained many LLM models, but I still feel like I will get some new, valuable information on this process from the book.